
Discover one R package a day by following the @RLangPackage account on Twitter! Inspired by One R Tip Day (@RLangTip) I created a Twitter bot that will feature one package with its description and GitHub URL each day. The R programming language (referred to as #rstats on Twitter) now has over 12,600 packages. Tweeting one each day would take more than 34 years to get through them all and that doesn’t even consider the rapid growth of new packages as shown in this post.
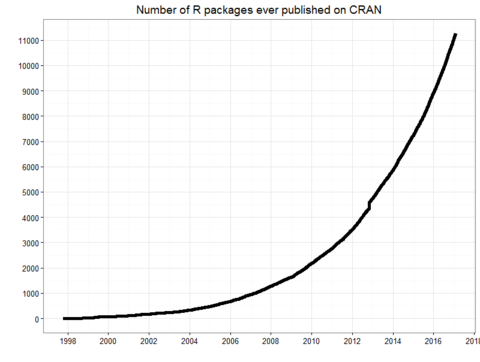
The purpose of the @RLangPackage Twitter account is to feature the diversity of packages that R has to offer. Most users have heard of ggplot2 and dplyr, but there are thousands of other great packages waiting to be discovered. In order to highlight those I took a list of all packages on CRAN and filtered it down to ones with anywhere between 5,000 and 1,000,000 CRAN downloads. I then took a subset of that with anywhere between 10 and 1,000 stars on GitHub. I decided to focus on these mildly popular packages with source code hosted on GitHub so that I can embed the link in the tweet and promote packages with code that people have already started to explore. After following those subsetting rules, one package is selected at random after narrowing to a list of packages that haven’t already been tweeted. I am hosting the bot on Heroku and using Heroku Scheduler to send out a tweet each day at 10:30am UTC or 6:30am Eastern Time. Below the credits and resources is the sloppily written Python that’s currently being hosted on Heroku and executed.
Credits
I was found a couple different blog posts on creating a Twitter bot with R, namely here and here, but they didn’t involve deploying on Heroku or another cloud service. However, there were plenty of Python based Twitter bot tutorials, so I took full advantage of them and went the Python route. Below is the host of resources I considered while figuring out how to deploy the app, what Twitter package to use, and some basic Python syntax which, embarrassingly, I should know by now. I think most users will gravitate towards the tweepy Python library but I found that it throws up an error when using it with Conda 3.6. The issue is documented on GitHub https://github.com/tweepy/tweepy/issues/894.
Resources
- Used as a general guide to deploying: http://briancaffey.github.io/2016/04/05/twitter-bot-tutorial.html
- Setting up credentials as config vars: https://devcenter.heroku.com/articles/config-vars
- How to load environment vars from file: https://robinislam.me/blog/reading-environment-variables-in-python/
- Timeline dump code: https://github.com/geduldig/TwitterAPI/blob/master/examples/dump_timeline.py
Full Script
# script.py
from os import environ
from os.path import join, dirname
from dotenv import load_dotenv
from re import sub
import pandas
from TwitterAPI import TwitterAPI, TwitterPager
# create .env file path
dotenv_path = join(dirname(__file__), '.env')
# load file from the path
load_dotenv(dotenv_path)
if __name__ == "__main__":
# connect to api
api = TwitterAPI(consumer_key=environ['TWITTER_CONSUMER_KEY'],
consumer_secret=environ['TWITTER_CONSUMER_SECRET'],
access_token_key=environ['TWITTER_ACCESS_TOKEN'],
access_token_secret=environ['TWITTER_ACCESS_TOKEN_SECRET'])
# scrape all prior tweets to check which packages I've already tweeted about
SCREEN_NAME = 'RLangPackage'
pager = TwitterPager(api,
'statuses/user_timeline',
{'screen_name': SCREEN_NAME, 'count': 100})
# parse out the package name that occurs before the hyphen at the beginning
previous_pks = []
for item in pager.get_iterator(wait=3.5):
if 'text' in item:
this_pkg = sub("^(\w+) - (.*)", "\\1", item['text'])
previous_pks.append(this_pkg)
# convert the package names to a dataframe
prev_df = pandas.DataFrame({'name': previous_pks})
prev_df.set_index('name')
# load the data I've compiled on R packages
url = "https://raw.githubusercontent.com/StevenMMortimer/one-r-package-a-day/master/r-package-star-download-data.csv"
all_df = pandas.read_csv(url)
all_df.set_index('name')
# do an "anti join" to throw away previously tweeted rows
all_df = pandas.merge(all_df, prev_df, how='outer', indicator=True)
all_df = all_df[all_df['_merge'] == 'left_only']
# focus on packages in middle ground of downloads and stars
filtered_df = all_df[all_df['stars'].notnull()]
filtered_df = filtered_df[filtered_df['stars'].between(10,1000)]
filtered_df = filtered_df[filtered_df['downloads'].notnull()]
filtered_df = filtered_df[filtered_df['downloads'].between(5000, 1000000)]
# randomly select one of the remaining rows
selected_pkg = filtered_df.sample(1)
# pull out the name and description to see if we need to
# truncate because of Twitters 280 character limit
prepped_name = selected_pkg.iloc[0]['name']
prepped_desc = sub('\s+', ' ', selected_pkg.iloc[0]['description'])
name_len = len(prepped_name)
desc_len = len(prepped_desc)
# 280 minus 3 for " - ", then minus 23 because links are counted as such,
# then minus 9 for the " #rstats " hashtag
if desc_len <= (280-3-23-9-name_len):
prepped_desc = prepped_desc[0:desc_len]
else:
prepped_desc = prepped_desc[0:(280-6-23-9-name_len)] + "..."
# cobble together the tweet text
TWEET_TEXT = prepped_name + " - " + prepped_desc + " #rstats " + selected_pkg.iloc[0]['github_url']
print(TWEET_TEXT)
# tweet it out to the world!
r = api.request('statuses/update', {'status': TWEET_TEXT})
print('SUCCESS' if r.status_code == 200 else 'PROBLEM: ' + r.text)