 I recently wrote a blog post here
comparing the number of CRAN downloads an R package gets relative to its number of
stars on GitHub. What I didn’t really think about during my analysis was whether or
not scraping CRAN was a violation of its Terms and Conditions. I simply copy and
pasted some code from R-bloggers
that seemed to work and went on my merry way. In hindsight, it would have been better
to check whether or not the scraping was allowed and maybe find a better way to
get the information I needed. Of course, there was a much easier way to get the
CRAN package metadata using the function
I recently wrote a blog post here
comparing the number of CRAN downloads an R package gets relative to its number of
stars on GitHub. What I didn’t really think about during my analysis was whether or
not scraping CRAN was a violation of its Terms and Conditions. I simply copy and
pasted some code from R-bloggers
that seemed to work and went on my merry way. In hindsight, it would have been better
to check whether or not the scraping was allowed and maybe find a better way to
get the information I needed. Of course, there was a much easier way to get the
CRAN package metadata using the function tools::CRAN_package_db() thanks to a hint
from Maëlle Salmon provided in this tweet:
Cool work! I see you scraped the data, you could get a table with all pkgs and an URL column via tools::CRAN_package_db() which is gentler for CRAN website I think.
— Maëlle Salmon (@ma_salmon) June 20, 2018
Not sure their website has a robots.txt but in general https://t.co/20TtlsGBOf is useful when webscraping 🙂
How to Check if Scraping is Permitted
Also provided by Maëlle’s tweet was the recommendation for using the robotstxt package (currently having 27 Stars + one Star that I just added!). It doesn’t seem to be well known as it only has 6,571 total downloads. I’m hoping this post will help spread the word. It’s easy to use! In this case I’ll check whether or not CRAN permits bots on specific resources of the domain.
My other blog post analysis originally started with trying to get a list of all
current R packages on CRAN by parsing the HTML from https://cran.rstudio.com/src/contrib. The page looks like this:
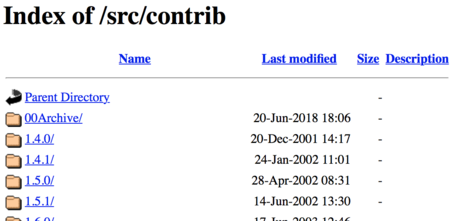
The question is whether or not scraping this page is permitted according to the
robots.txt file on the cran.rstudio.com domain. This is where the
robotstxt package can help us out. We can check simply by supplying the
domain and path that is used to form the full link we are interested in
scraping. If the paths_allowed() function returns TRUE then we should be
allowed to scrape, if it returns FALSE then we are not permitted to scrape.
library(robotstxt)
paths_allowed(
paths = "/src/contrib",
domain = "cran.rstudio.com",
bot = "*"
)
#> [1] TRUEIn this case the value that is returned is TRUE meaning that bots are allowed to scrape that
particular path. This was how I originally scraped the list of current R packages, even though
you don’t really need to do that since there is the wonderful function tools::CRAN_package_db().
After retrieving the list of packages I decided to scrape details from the DESCRIPTION
file of each package. Here is where things get interesting. CRAN’s robots.txt file shows that scraping the
DESCRIPTION file of each package is not allowed.
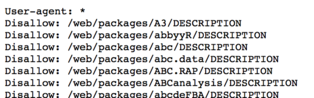 Furthermore, you can verify this using the robotstxt package:
Furthermore, you can verify this using the robotstxt package:
paths_allowed(
paths = "/web/packages/ggplot2/DESCRIPTION",
domain = "cran.r-project.org",
bot = "*"
)
#> [1] FALSEHowever, when I decided to scrape the package metadata I did it by parsing the HTML
from the canonical package link that resolves to the index.html page for the package. For
example, https://cran.r-project.org/package=ggplot2
resolves to https://cran.r-project.org/web/packages/ggplot2/index.html. If you check whether scraping is allowed on this page, the robotstxt package
says that it is permitted.
paths_allowed(
paths = "/web/packages/ggplot2/index.html",
domain = "cran.r-project.org",
bot = "*"
)
#> [1] TRUE
paths_allowed(
paths = "/web/packages/ggplot2",
domain = "cran.r-project.org",
bot = "*"
)
#> [1] TRUEThis is a tricky situation because I can access the same information that is in the
DESCRIPTION file just by going to the index.html page for the package where scraping
seems to be allowed. In the spirit of respecting CRAN it logically follows that I should
not be scraping the package index pages if the individual DESCRIPTION files are off-limits.
This is despite there being no formal instruction from the robots.txt file about package
index pages. All in all, it was an interesting bit of work and glad that I was able
to learn about the robotstxt package so I can have it in my toolkit going forward.
DISCLAIMER: I only have a basic understanding of how robots.txt files work
based on allowing or disallowing specified paths. I believe in this case CRAN’s
robots.txt broadly permitted scraping, but too narrowly disallowed just the DESCRIPTION
files. Perhaps this goes back to an older time where those DESCRIPTION files really
were the best place for people to start scraping so it made sense to disallow them.
Or the reason could be something else entirely.
UPDATE: David G. Johnston messaged me and brought up an important point that
the robots.txt file primarily is used to tell search engines whether or not
to crawl certain portions of a domain. The “Terms of Use” might be a better place
to begin looking for any limitations on the usage of the data for the type of project
you are creating.